Not much more to say that the title.
We are pulling plaintext ticket descriptions and notes from Autotask with n8n via the API, and in many cases passing them to an LLM.
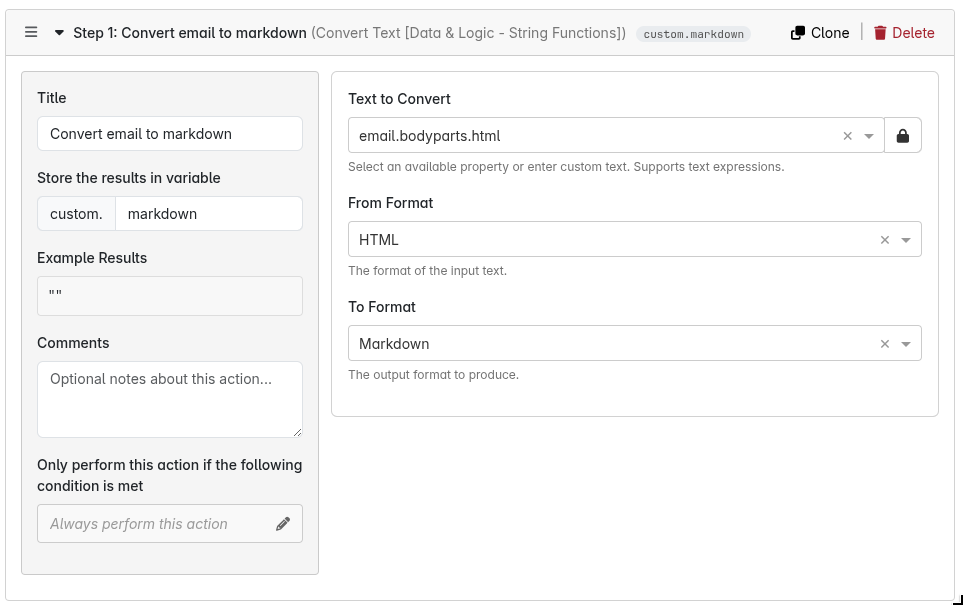
Having them in markdown format would significantly increase the value proposition.
This new action step gives you the ability to convert any text between plaintext, HTML, and Markdown (not just the email body). I couldn’t think of any more formats besides those 3, but we’d be happy to consider adding more formats if you have any more that would be helpful.
I have tested this and it’s working great as a replacement for {{email.bodyparts.html_to_plaintext}}.
However, I would much prefer to use {{email.body_stripped.visible}} in some cases, and that is only available to me in plaintext?
If anyone else comes across this problem I have solved it by implementing my own analogue for body_stripped.visible.
Basically, the issue was that an email would arrive with a long chain of replies, and all of this was being added as note updates to tickets.
I have used a regex to identify the From: or ‘wrote’ lines indicating the start of the last email send from my company domain. And if it’s found, only use the text before this match.
This way, multiple emails sent after our last addition to the chain will appear, but from our last addition back will be stripped.
This does not help with the email signatures, but it is a huge improvement over adding the entire chain to every note.
Thanks for reporting this, @Mark . We just released a release to the beta console that uses a different markdown conversion process. It seems to do a much better job.
This is live on the beta console right now (NOT on the production flow). You can test it only by manually “Reprocessing” a message in your history when viewing it on the beta console. For example, you can re-process the example you gave earlier here:
Please see MSPintegrations
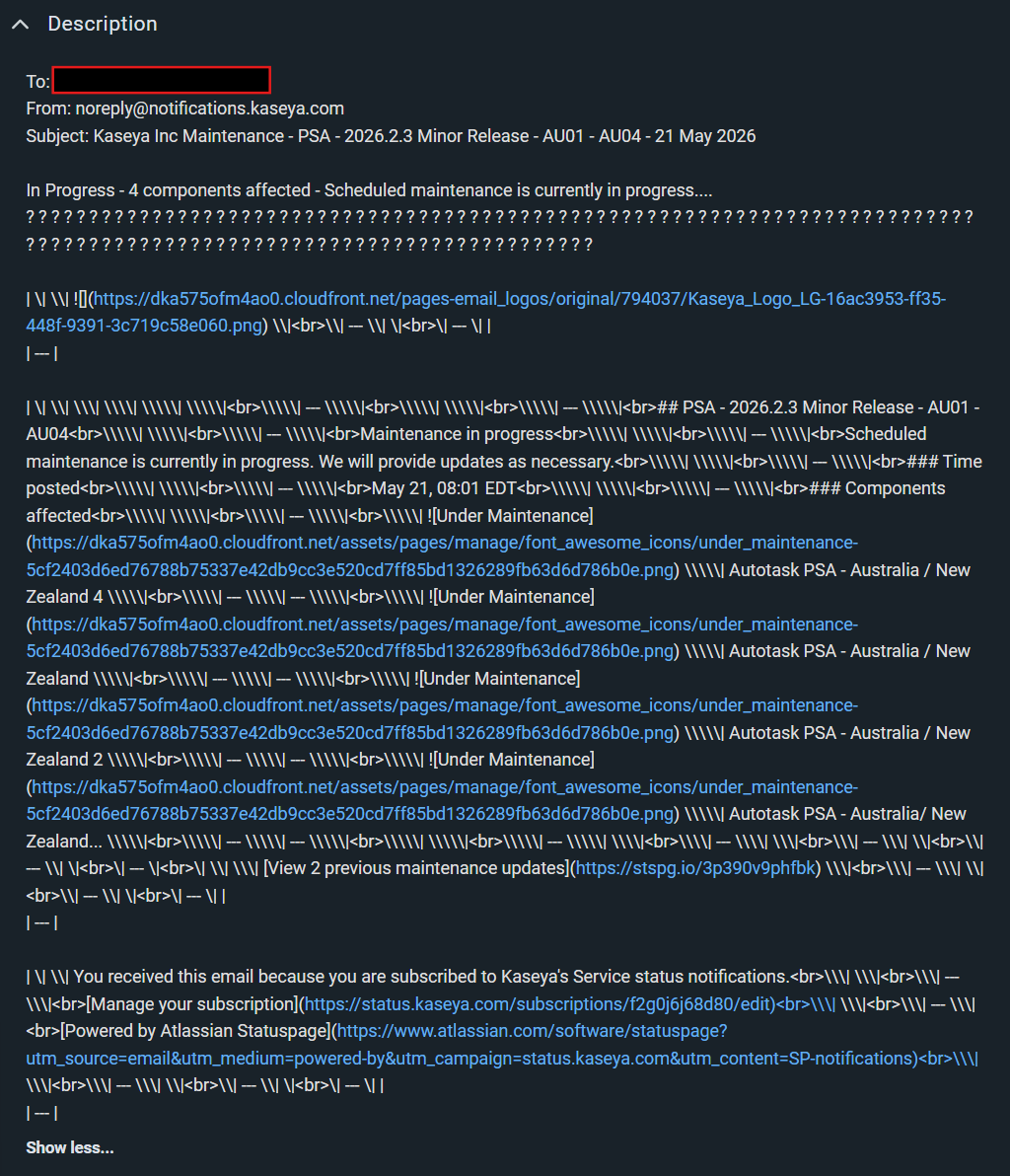
The bottom half of the body text (content after “May 21, 09:00 EDT ### Components affected”), seems to be missing in the markdown.